Video
Abstract
Human beings are social animals. How to equip 3D autonomous characters with similar social intelligence that can perceive, understand and interact with humans remains an open yet foundamental problem.
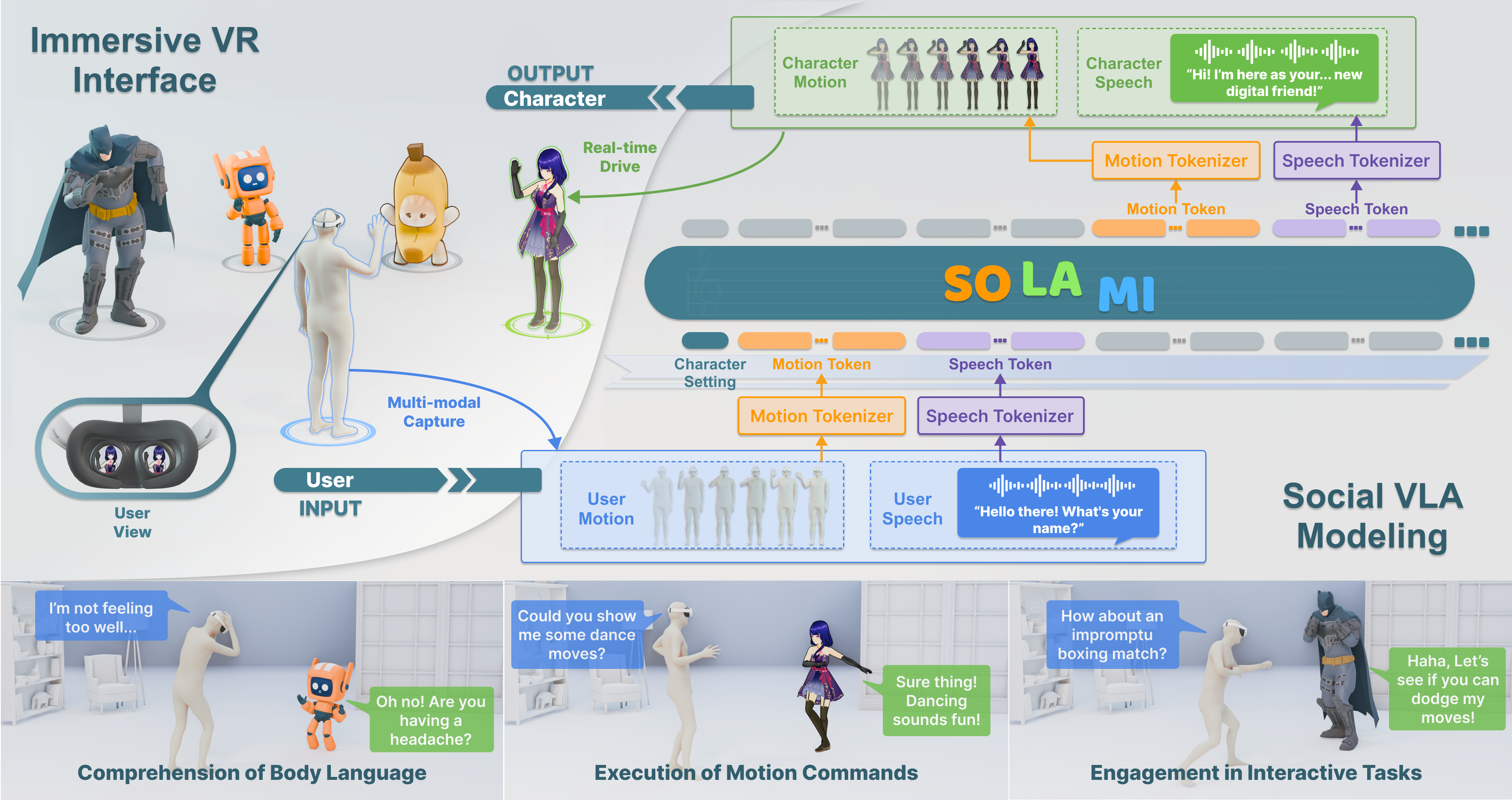
In this paper, we introduce SOLAMI, the first end-to-end Social vision-Language-Action (VLA) Modeling framework for Immersive interaction with 3D autonomous characters. Specifically, SOLAMI builds 3D autonomous characters from three aspects: (1) Social VLA Architecture: We propose a unified social VLA framework to generate multimodal response (speech and motion) based on the user's multimodal input to drive the character for social interaction. (2) Interactive Multimodal Data: We present SynMSI, a synthetic multimodal social interaction dataset generated by an automatic pipeline using only existing motion datasets to address the issue of data scarcity. (3) Immersive VR Interface: We develop a VR interface that enables users to immersively interact with these characters driven by various architectures. Extensive quantitative experiments and user studies demonstrate that our framework leads to more precise and natural character responses (in both speech and motion) that align with user expectations with lower latency.
Future Work
Input Modality: For dyadic social interaction, using the user's body motion and speech as input is sufficient. However, when considering multi-person interaction or interaction involving the environment and objects, video or dynamic 3D scenes might be a better choice;
Data Collection: Our synthetic dataset, SynMSI, enables satisfactory user evaluation results. However, collecting real-time data of actual dyadic interaction could enable our model to generate more precise and natural body language and speech, while also supporting duplex streaming conversations, similar to Body of Her or GLM-4-Voice. Compared to text and video modalities, the collection of embodied 3D data is undoubtedly challenging. Potential solutions include: capturing or learning human behavioral data from existing video datasets, building immersive interaction platforms to gather data on human interactions, and using surrogate control to collect data from human interactions with 3D characters;
Cross Embodiment: Using a unified SMPL-X model to represent characters' motion inevitably introduces challenges in cross-embodiment for different characters. While some degree of error and misalignment may not hinder information exchange in social language interaction, such representations clearly lack generalizability for fine-grained tasks (e.g., handshaking, object manipulation). The challenges of retargeting in 3D human-related tasks and cross-embodiment in robotics share similarities, providing opportunities for mutual inspiration and methodological exchange;
Long-Short Term Design: Although SOLAMI demonstrates effective modeling for real-time interactions, its architecture encounters challenges such as computational redundancy, forgetting, and training difficulties during extended social interactions. A promising direction (such as thinking fast and slow) to explore is integrating long-term memory, knowledge, and skills with short-term real-time interaction. This approach could ensure interaction quality while reducing computational overhead and simplifying the training process;
Efficient Learning Method: Although our dataset, SynMSI, tries to collect large-scale motion data, the inherently long-tail distribution of human motions results in some behaviors having very low occurrence frequencies. In particular, the data volume for signature actions of 3D characters is inherently limited. While models like GPT-3 have demonstrated remarkable few-shot learning capabilities, the data-intensive training required is currently unsustainable in the field of digital humans. Therefore, exploring effective learning methods is essential. Leveraging character-focused knowledge embedded in existing foundation models or incorporating human evaluators to guide the model in learning new skills from a small number of samples are promising research directions.
Acknowledgments
We extend our sincere gratitude to Fei Xia, Huazhe Xu, Tao Kong, Jiangyong Huang for their insights from the embodied intelligence field. We thank Mingyuan Zhang, Fangzhou Hong, and Xinying Guo for discussions on motion generation, Bo Li and Yuanhan Zhang for advice on multimodal model training. We would also like to acknowledge Han Du, Fanzhou Wang, Jiaqi Li, Liang Pan, Peng Gao, and Yukun Wei for insightful discussions on the topic.
If you are interested in our work, please feel free to contact us at alanjjp98@gmail.com.
BibTeX
@inproceedings{Jiang2025SOLAMI,
title={SOLAMI: Social Vision-Language-Action Modeling for Immersive Interaction with 3D Autonomous Characters},
author={Jianping Jiang, Weiye Xiao, Zhengyu Lin, Huaizhong Zhang, Tianxiang Ren, Yang Gao, Zhiqian Lin, Zhongang Cai, Lei Yang, Ziwei Liu},
booktitle={CVPR},
year={2025}
}